
Spring循环依赖
西魏陶渊明 ... 2022-3-24 大约 9 分钟

作者: 八阿哥的剑
博客: https://springlearn.cn
一日一句毒鸡汤
问世间钱为何物,只叫人生死相许。!😄
写文章不容易,如果感觉还行,请点个关注,点关注不迷路。
# 一、什么是循环依赖
这种简单的问题,直接伪代码吧。
@Service
public class A {
@Autowired
private B b;
}
@Service
public class B {
@Autowired
private A a;
}
1
2
3
4
5
6
7
8
9
10
11
2
3
4
5
6
7
8
9
10
11
我中有你,你中有我。
# 二、解决循环依赖思路
思路其实非常简单还是用伪代码来说明
A a = new A();
B b = new B();
a.setB(b);
b.setA(a);
1
2
3
4
2
3
4
思路就是这么简单,先分别把A和B给实例化。 这时候实例化的A和B仅仅是完成了实例化,内部的属性其实都没有。 只有当执行了3、4行才算正常完成。
A a = new A();
B b = new B();
a.setB(b);
b.setA(a);
1
2
3
4
2
3
4
通过上面的代码我们总结下,要想实现循环注入。首先要满足第一个条件。
- 能被实例化
- 有空构造
- 或有构造且构造参数满足能被实例化。
好了,知道这点就成了,相信让你来实现循环注入,应该也可以了吧。其实就这么简单 ?
那我们来看Spring如何来实现的。相信看完你就头大了。但是没关系,基本原理你已经知道了。 带着这个思路来看Spring的源码就简单了。
# 三、Spring如何解决循环依赖
首先我们要知道Spring中的bean, 有两种形式。
- 第一种是单例。所谓单例就是容器中这个类,只会存在一个实例。不管你调用了多少次
getBean(String beanName)返回的都是一个实例(因为每次都从缓存中获取的实例)。 - 第二种是原型。所谓原型就是容器中这个类,没有缓存。每次都是新建一个Bean。
在这里我们思考下,如果要你来实现循环注入,以上两种模式。你能用那一个?
要想实现循环注入,即这个Bean必须要有一个缓存的地方。不然每次都是创建,虽然能完成实例化,但是实例化后,需要注入的 bean 无法实现注入,就会陷入死循环。
这里第二个必要因素就出来了。
2. 必须要是单例
好了,知道这么多我们开始看源码吧。
# 3.1 Spring中创建Bean的步骤
- 实例化,createBeanInstance,就是new了个对象。
- 属性注入,populateBean, 就是 set 一些属性值。
- 初始化,initializeBean,执行一些 aware 接口中的方法,initMethod,AOP代理等
# 3.2 循环依赖三层缓存
注意看细节,每个缓存的数据类型是什么? 后面要考。

- 一级缓存
Map<String, Object> singletonObjects- 如果等于空,或者当前单例正在创建中(即只完成了实例化)。就从二级缓存中获取。
- 二级缓存
Map<String, Object> earlySingletonObjects- 如果等于空,就从三级缓存中获取。
- 三级缓存
Map<String, ObjectFactory<?>> singletonFactories- 创建Bean的一个工厂,允许容器中定义特殊的,生成Bean的方法。使用
addSingletonFactory
- 创建Bean的一个工厂,允许容器中定义特殊的,生成Bean的方法。使用
其实要想实现循环依赖只用2个缓存就行。三级缓存的意义是为了完成某些功能。至于什么功能呢? 这里先不说后面看流程。
protected Object getSingleton(String beanName, boolean allowEarlyReference) {
Object singletonObject = this.singletonObjects.get(beanName);
if (singletonObject == null && isSingletonCurrentlyInCreation(beanName)) {
synchronized (this.singletonObjects) {
singletonObject = this.earlySingletonObjects.get(beanName);
if (singletonObject == null && allowEarlyReference) {
ObjectFactory<?> singletonFactory = this.singletonFactories.get(beanName);
if (singletonFactory != null) {
singletonObject = singletonFactory.getObject();
this.earlySingletonObjects.put(beanName, singletonObject);
this.singletonFactories.remove(beanName);
}
}
}
}
return singletonObject;
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
好我们知道有这两个缓存就继续往下看源码。当 getSingleton 是 null。继续往下走。其他源码就跳过了,不是本篇的主要内容,我们只看
解决循环依赖的核心代码。
- doCreateBean#createBeanInstance 先实现实例化。
- 当前bean是单例,不会添加到二级缓存,直接就添加到三级缓存中,注意这里不是添加的Bean,而是生成Bean的工厂方法
ObjectFactory(#getEarlyBeanReference)。
boolean earlySingletonExposure = (mbd.isSingleton() && this.allowCircularReferences &&
isSingletonCurrentlyInCreation(beanName));
if (earlySingletonExposure) {
if (logger.isTraceEnabled()) {
logger.trace("Eagerly caching bean '" + beanName +
"' to allow for resolving potential circular references");
}
addSingletonFactory(beanName, () -> getEarlyBeanReference(beanName, mbd, bean));
}
1
2
3
4
5
6
7
8
9
2
3
4
5
6
7
8
9
- doCreateBean#populateBean 实现属性注入
以上面的代码的例子,A创建时候被加入到了三级缓存中,然后继续执行 populateBean。发现要依赖B。然后依次从缓存中
来找这个A。最终在三级缓存中读取到了B。然后实现注入。这里三级缓存中的 Bean。 有可能只是完成了 new。但是容器
不管,先完成循环注入。至于注入的东西是否是完全品还是半成品不关心,因为都是单例所以,后面在注入属性也没关系。
这里我们知道单例的用处了吧。试想一下,如果不是单例模式,而是原型模式。那么bean就必须是完全品,不然就陷入了死循环。
下面我们还用伪代码的方式再来说一篇实现思路。
// createBeanInstance先实例化,然后加入到三级缓存中
A a = new A();
// a在执行populateBean的时候,发现要注入属性B,于是就使用getBean。
// getBean(b) 执行createBeanInstance先实例化
B b = new B();
// 然后加入到三级缓存中,b在执行populateBean注入属性值的时候。发现也依赖了A。
// 然后从缓存中找到办成品A。于是乎B的注入就完成,然后再执行B的init方法。
b.setA(a);
// B完成后,则返回到A的populateBean也注入了B。然后在执行A的init方法
a.setB(b);
1
2
3
4
5
6
7
8
9
10
2
3
4
5
6
7
8
9
10
到这里就完成了循环注入,这里有点绕,小编画了一个图,大家跟着序号来看,然后好好理解下。
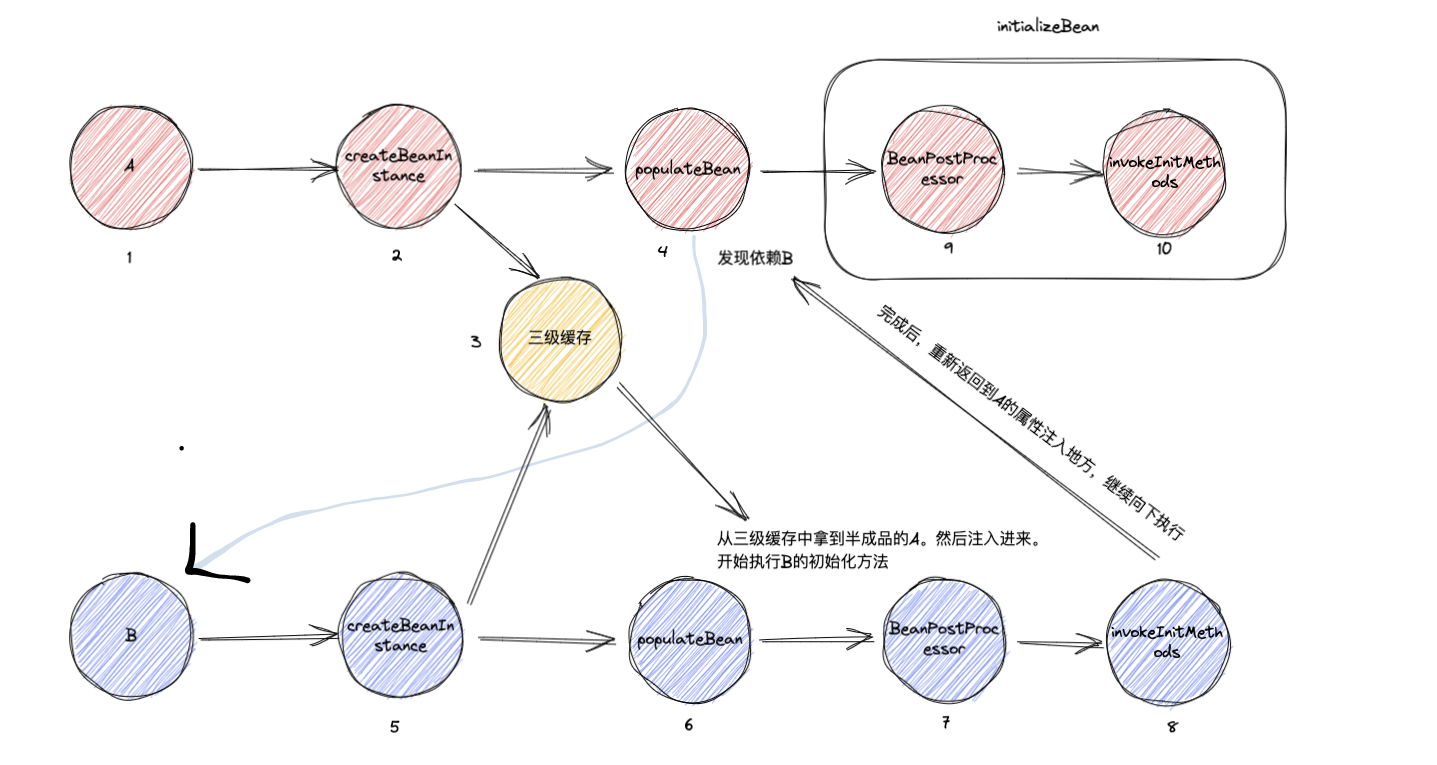
通过这个图其实我们能发现一个问题。B此时从三级缓存中拿到的A是一个半成品的A。 假如B在执行初始化方法的时候,依赖A的populateBean注入的属性。那么此时一定会拿不到的。 下面写点伪代码,说一下这个问题。
# 3.3 发现点问题
# 3.3.1 半成品问题-1
@Component
public class A implements InitializingBean {
@Autowired
private B b;
@Value("${a.name}")
private String name;
public String getName() {
return name;
}
@Override
public void afterPropertiesSet() throws Exception {
System.out.println("A:" + b);
}
}
@Component
public class B implements InitializingBean {
@Autowired
private A a;
@Override
public void afterPropertiesSet() throws Exception {
System.out.println("B:" + a.getName());
}
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
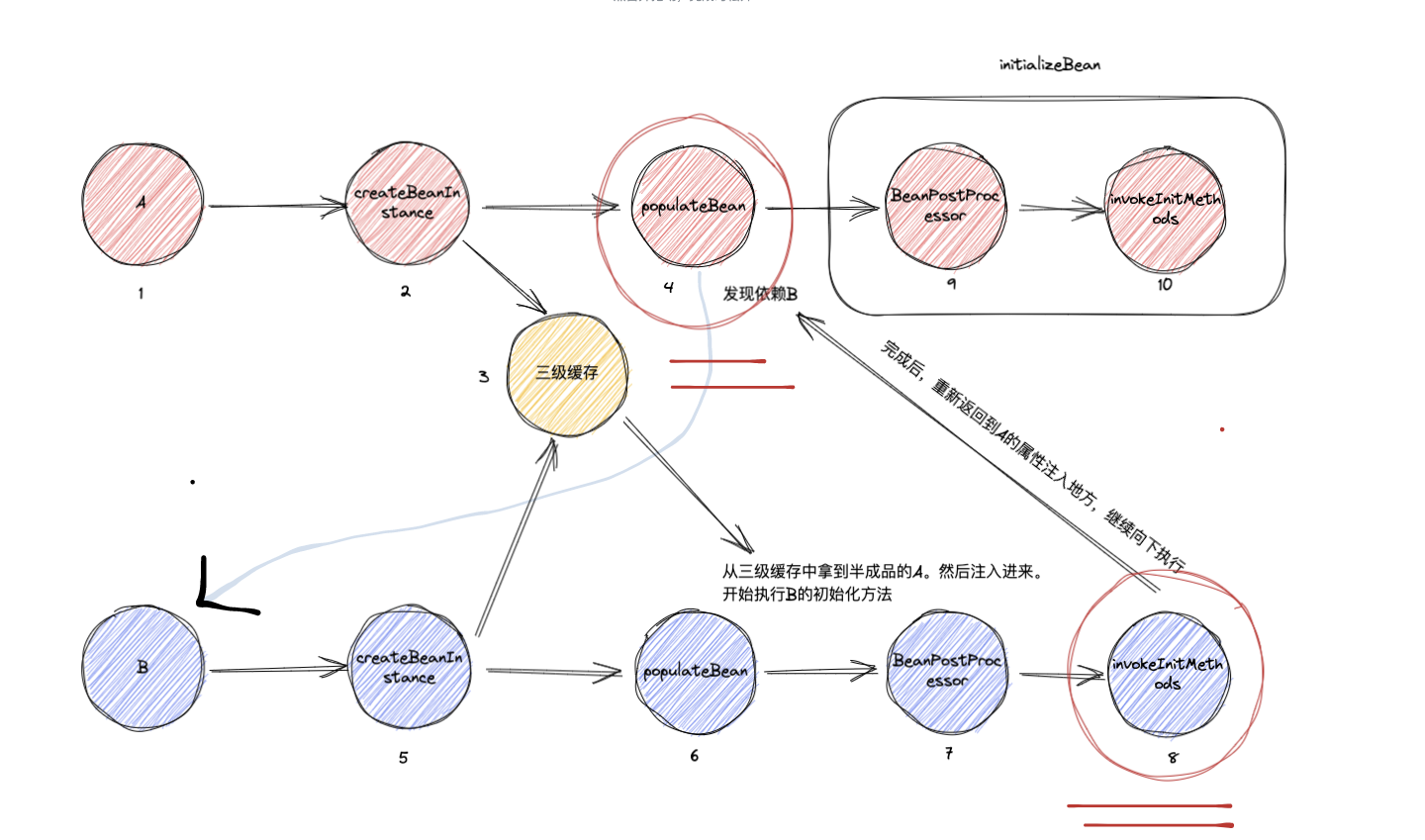
通过上图我们知道B会先执行初始化,而这里B的初始化 (图例8) 会依赖A的参数注入 (图例4) 。而B在执行初始化的时候。A(图例4没有完全完成注入)并没有完成属性注入。 那么我们此时在拿到A的getName一定是空的。
以上代码执行就是:
B:null
A:com.example.demo.B@38aa816f
1
2
2
# 3.3.2 半成品问题-2
A的BeanPostProcessor没有执行,那么假如我们想要对A进行方法代理。B在执行初始化的时候,调用A的 getName。会成功代理上吗?
@Component
public class A implements InitializingBean {
@Autowired
private B b;
private final String name = "孙悟空";
public String getName() {
return name;
}
@Override
public void afterPropertiesSet() throws Exception {
System.out.println("A:" + b);
}
}
@Component
public class B implements InitializingBean {
@Autowired
private A a;
@Override
public void afterPropertiesSet() throws Exception {
System.out.println("B:" + a.getName());
}
}
@Aspect
@Component
public class AopConfig {
/**
* 精确匹配类名
*/
@Pointcut("within(A)")
private void matchClass() {
}
@Before("matchClass()")
public void beforeMatchClassName() {
System.out.println("--------精确匹配类名-------");
}
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
执行结果:
--------精确匹配类名-------
B:孙悟空
A:com.example.demo.B@5e01a982
1
2
3
2
3
发现疑问了吗? 前面我们说了,在执行B图例8的时候(b的初始化方法),A图例9并没有执行,那为什么这里会代理成功呢?
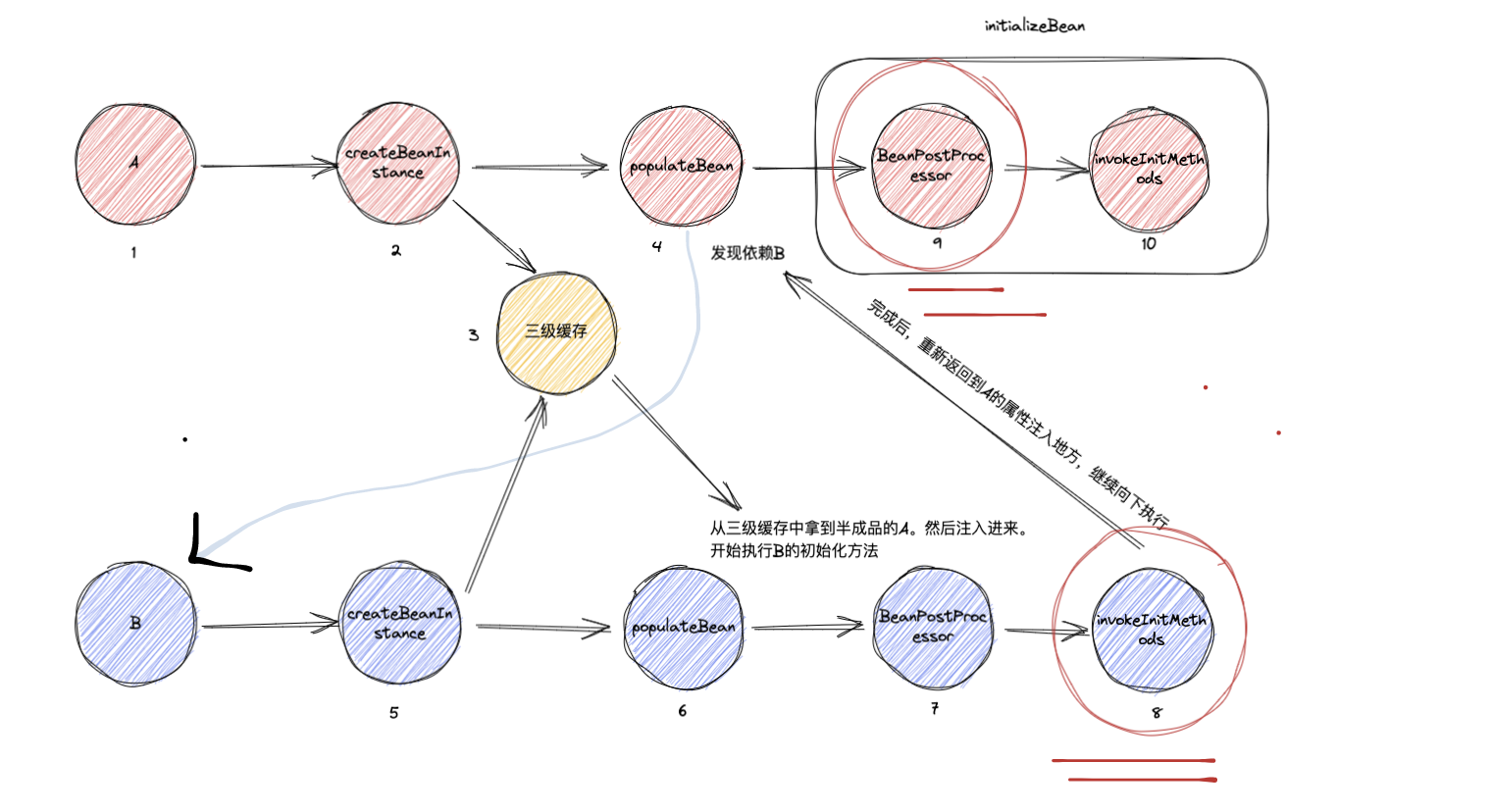
答案揭晓
这里在添加缓存的时候,并不是直接把实例添加到缓存中的。 而是将图例9的逻辑,封装到 ObjectFactory的方式添加到缓存中的。 ObjectFactory#getObject时候执行了Bean 的处理。(AOP代理等)
注意: 这里并不是把所有的处理器都包装到ObjectFactory方法中,而是有选择的使用,只有实现了SmartInstantiationAwareBeanPostProcessor接口 才会放到里面。
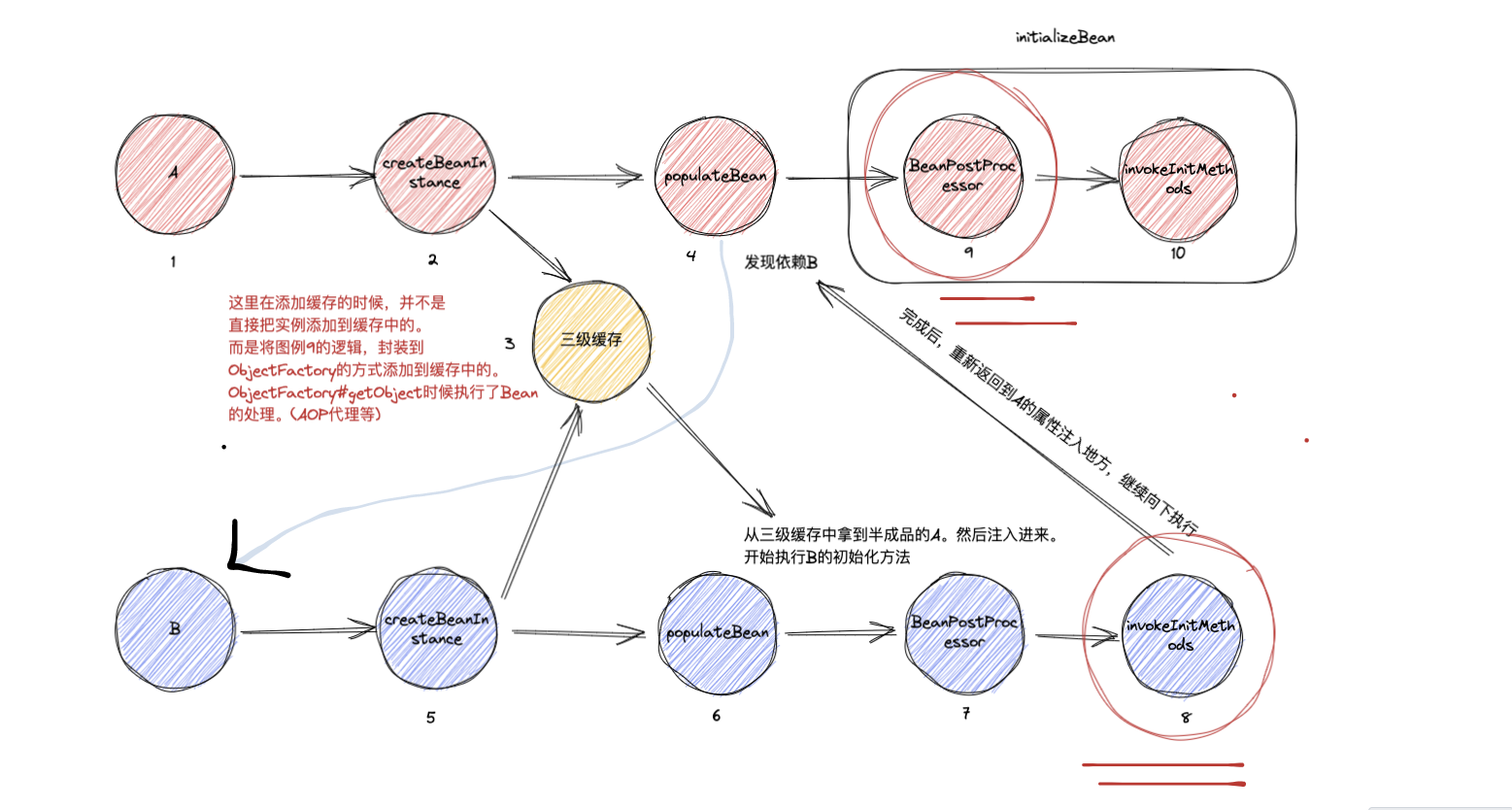
答案就在这里,这里执行了。一些特殊逻辑的处理器。当实现了 SmartInstantiationAwareBeanPostProcessor 接口。
就可以提前对那些半成品的Bean进行处理。
protected Object getEarlyBeanReference(String beanName, RootBeanDefinition mbd, Object bean) {
Object exposedObject = bean;
if (!mbd.isSynthetic() && hasInstantiationAwareBeanPostProcessors()) {
for (SmartInstantiationAwareBeanPostProcessor bp : getBeanPostProcessorCache().smartInstantiationAware) {
exposedObject = bp.getEarlyBeanReference(exposedObject, beanName);
}
}
return exposedObject;
}
1
2
3
4
5
6
7
8
9
2
3
4
5
6
7
8
9
比如AOP的实现类。
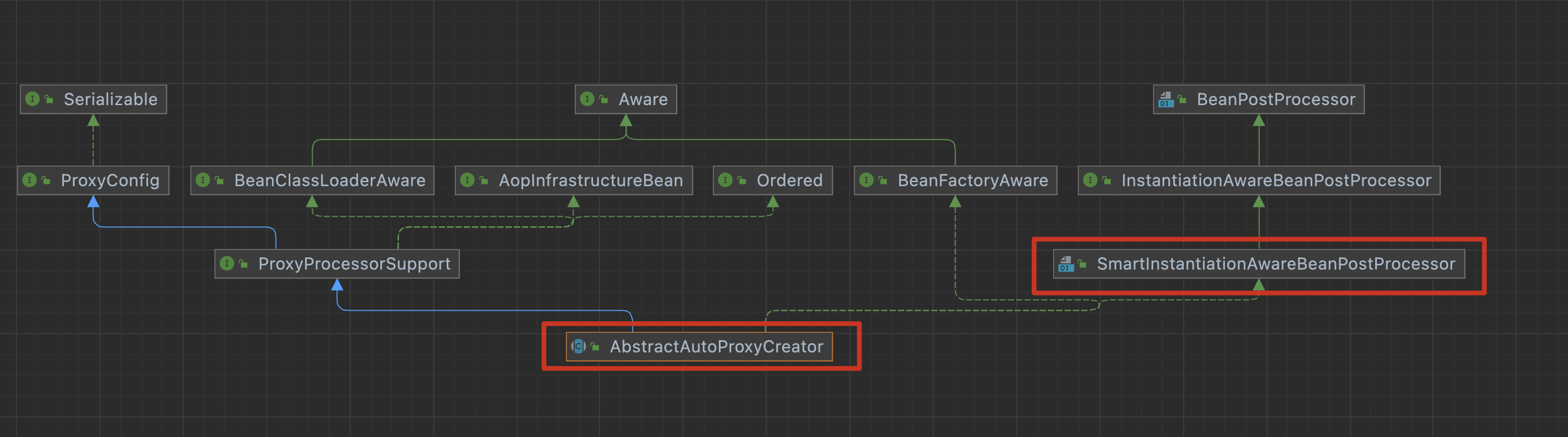
这里我们在思考一个问题。A半成品的时候被AOP代理了一次,那么当A在执行Bean处理器的时候岂不是有要被代理一次吗?
AbstractAutoProxyCreator#getEarlyBeanReference
第一次代理时候会被加到缓存中。
public Object getEarlyBeanReference(Object bean, String beanName) {
Object cacheKey = this.getCacheKey(bean.getClass(), beanName);
this.earlyProxyReferences.put(cacheKey, bean);
return this.wrapIfNecessary(bean, beanName, cacheKey);
}
1
2
3
4
5
2
3
4
5
第二次时候在执行AOP后置处理器,会先判断缓存,如果缓存中存在就不在处理了。
public Object postProcessAfterInitialization(@Nullable Object bean, String beanName) {
if (bean != null) {
Object cacheKey = this.getCacheKey(bean.getClass(), beanName);
if (this.earlyProxyReferences.remove(cacheKey) != bean) {
return this.wrapIfNecessary(bean, beanName, cacheKey);
}
}
return bean;
}
1
2
3
4
5
6
7
8
9
10
2
3
4
5
6
7
8
9
10
# 四、知识点总结
# 4.1 满足循环依赖的条件是什么?
- 必须是单例模式
- 循环依赖类,必须能实例化(空构造,或构造参数满足循环依赖条件)
# 4.2 循环依赖可能导致什么问题?
在执行初始化的时候,如果初始化方法,依赖循环来的属性注入参数,可能导致获取不到数据信息的情况
如上面问题1。
# 4.3 为什么要用三级缓存而不是二级缓存?
为了满足Spring声明周期方法,即对半成品的B进行提前生命周期处理。如实现AOP。
# 五、开放性问题
只使用一级缓存,和三级缓存是否就能解决循环依赖,并且满足bean一些特殊逻辑处理呢(eg:aop)?
protected Object getSingleton(String beanName, boolean allowEarlyReference) {
// Quick check for existing instance without full singleton lock
Object singletonObject = this.singletonObjects.get(beanName);
if (singletonObject == null && isSingletonCurrentlyInCreation(beanName)) {
singletonObject = this.earlySingletonObjects.get(beanName);
if (singletonObject == null && allowEarlyReference) {
synchronized (this.singletonObjects) {
// Consistent creation of early reference within full singleton lock
singletonObject = this.singletonObjects.get(beanName);
if (singletonObject == null) {
singletonObject = this.earlySingletonObjects.get(beanName);
if (singletonObject == null) {
ObjectFactory<?> singletonFactory = this.singletonFactories.get(beanName);
if (singletonFactory != null) {
singletonObject = singletonFactory.getObject();
this.earlySingletonObjects.put(beanName, singletonObject);
this.singletonFactories.remove(beanName);
}
}
}
}
}
}
return singletonObject;
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
小编回答: 仅仅使用1级缓存和3级缓存完全可以的。
之所以使用2级缓存是因为三级缓存是ObjectFactory#getObject()。是每次都从工厂里面去拿。而使用了2级缓存,仅仅是为了提高性能。 而设计的。所以一单这个单例Bean完成后。会里面把二级和三级缓存给移除掉。
protected void addSingleton(String beanName, Object singletonObject) {
synchronized (this.singletonObjects) {
this.singletonObjects.put(beanName, singletonObject);
this.singletonFactories.remove(beanName);
this.earlySingletonObjects.remove(beanName);
this.registeredSingletons.add(beanName);
}
}
1
2
3
4
5
6
7
8
2
3
4
5
6
7
8
