
一致性hash问题
西魏陶渊明 ... 2022-5-22 大约 2 分钟

# 一、介绍
一致性哈希主要解决的问题,是互联网中的热点问题,及当cache环境改变,能动态感知,避免继续向已经坏掉的空间,插入新值.
# 二、不一致会有什么问题?
# 2.1 缓存的例子
有 N 个 cache 服务器(后面简称 cache ),那么如何将一个对象 object 映射到 N 个 cache 上呢,你很可能会采用类似下面的通用方法计算 object 的 hash
求余算法: hash(Object) % N
有多个cache: cache[0] cache[1] cache[2] cache[3], 然后要
put 4%4 insert 到cache[0]=A
put 1%4 insert 到cache[1]=B
put 2%4 insert 到cache[2]=C
put 3%4 insert 到cache[3]=D
假如cache[0] A节点突然挂了,此时获取cache[0]会有问题,put 5%3(本来4个节点-1一个节点) insert cache[2] ,之前是插入C,但是之后cache[2]=D,此时,一台错误会对全局产生影响.(因为cache的位置都发生了变化),这样就不能维护hash算法的单调性,可能之前已经插入了,但是后面就要覆盖.
cache[0]=A
- cache[0]=B
- cache[1]=C
- cache[2]=D
# 2.3 数据迁移例子
假如有10条数据,3个节点,如果按照取模的方式。
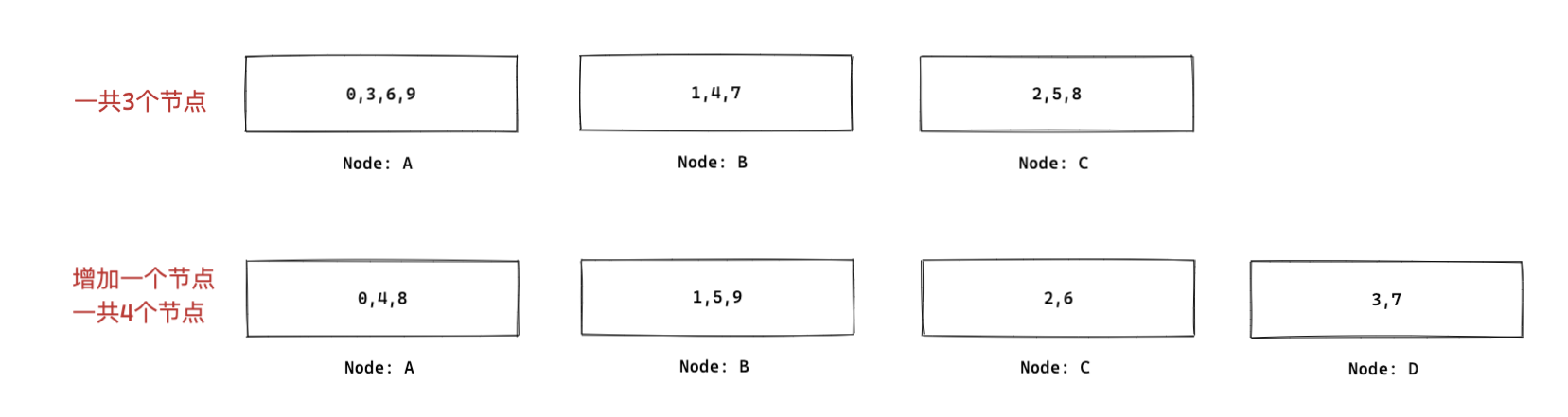
总结: 数据在增加了一个节点后,3,4,5,6,7,8,9都需要做搬迁,成本太高了
那么采用一致性hash后怎么样呢?
# 2.3.1 一致性hash如何处理?
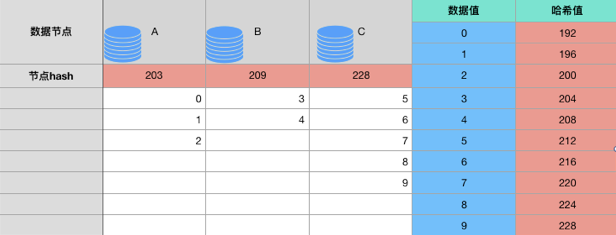
对 a b c 分别做哈希映射

当大于228都存203节点,于是就维护了一个圆形,即所有数据都能找到其节点了
当新加入节点d,可以算出d的hash
node d: 216
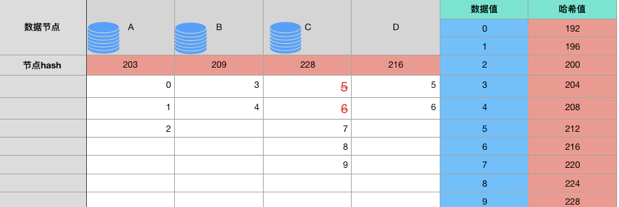
对数据进行迁移(其实只影响209~216之间的数,即达到了我们的目的)
# 三、总结
一致性hash的算法,就是不去确定唯一的下标,而是将节点先形成一个hash环,每次获取当前hash最近的节点。这样就算挂了一个节点,影响也是最小的。
