
Elastic-Job源码解析(三)之分片定时任务执行
西魏陶渊明 ... 2022-8-22 大约 6 分钟
通过本篇的阅读你将学会了解Elastic-Job的定时时机,及如何通过分片方式做一个分布式的定时任务框架。了解常用的三种分片策略,及如何自定义分布式分片策略
# Elastic-Job如何通过SpringJobScheduler启动定时
在<<Elastic-Job源码解析(一)之与Spring完美整合>>中我们已经了解Elasti-Job非常巧妙的用BeanDefinitionParse解析器将任务类型最终通过抽象类的方式解析成了SpringJobScheduler
- SpringJobScheduler
public abstract class AbstractJobBeanDefinitionParser extends AbstractBeanDefinitionParser {
@Override
protected AbstractBeanDefinition parseInternal(final Element element, final ParserContext parserContext) {
BeanDefinitionBuilder factory = BeanDefinitionBuilder.rootBeanDefinition(SpringJobScheduler.class);
factory.setInitMethodName("init");
//TODO 抽象子类
if ("".equals(element.getAttribute(JOB_REF_ATTRIBUTE))) {
if ("".equals(element.getAttribute(CLASS_ATTRIBUTE))) {
factory.addConstructorArgValue(null);
} else {
factory.addConstructorArgValue(BeanDefinitionBuilder.rootBeanDefinition(element.getAttribute(CLASS_ATTRIBUTE)).getBeanDefinition());
}
} else {
factory.addConstructorArgReference(element.getAttribute(JOB_REF_ATTRIBUTE));
}
factory.addConstructorArgReference(element.getAttribute(REGISTRY_CENTER_REF_ATTRIBUTE));
factory.addConstructorArgValue(createLiteJobConfiguration(parserContext, element));
BeanDefinition jobEventConfig = createJobEventConfig(element);
if (null != jobEventConfig) {
factory.addConstructorArgValue(jobEventConfig);
}
factory.addConstructorArgValue(createJobListeners(element));
return factory.getBeanDefinition();
}
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
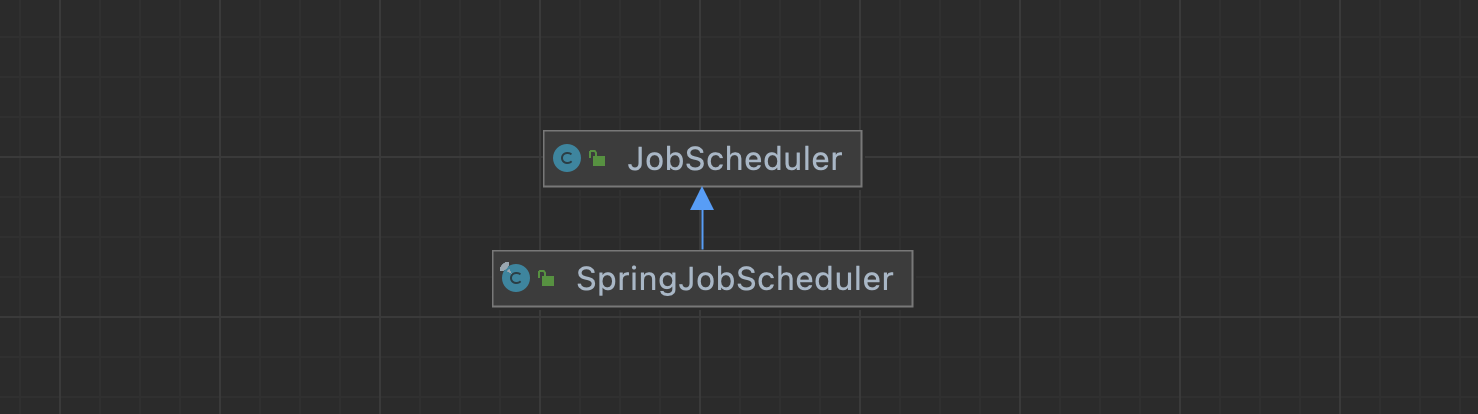
通过抽象类的方式解析成了SpringJobScheduler 我们看SpringJobScheduler定时器的架构,SpringJobScheduler就是一个定时器,是JobScheduler的子类。真正定时的逻辑是由JobScheduler类处理的包括上面的init方法和shutdown方法。
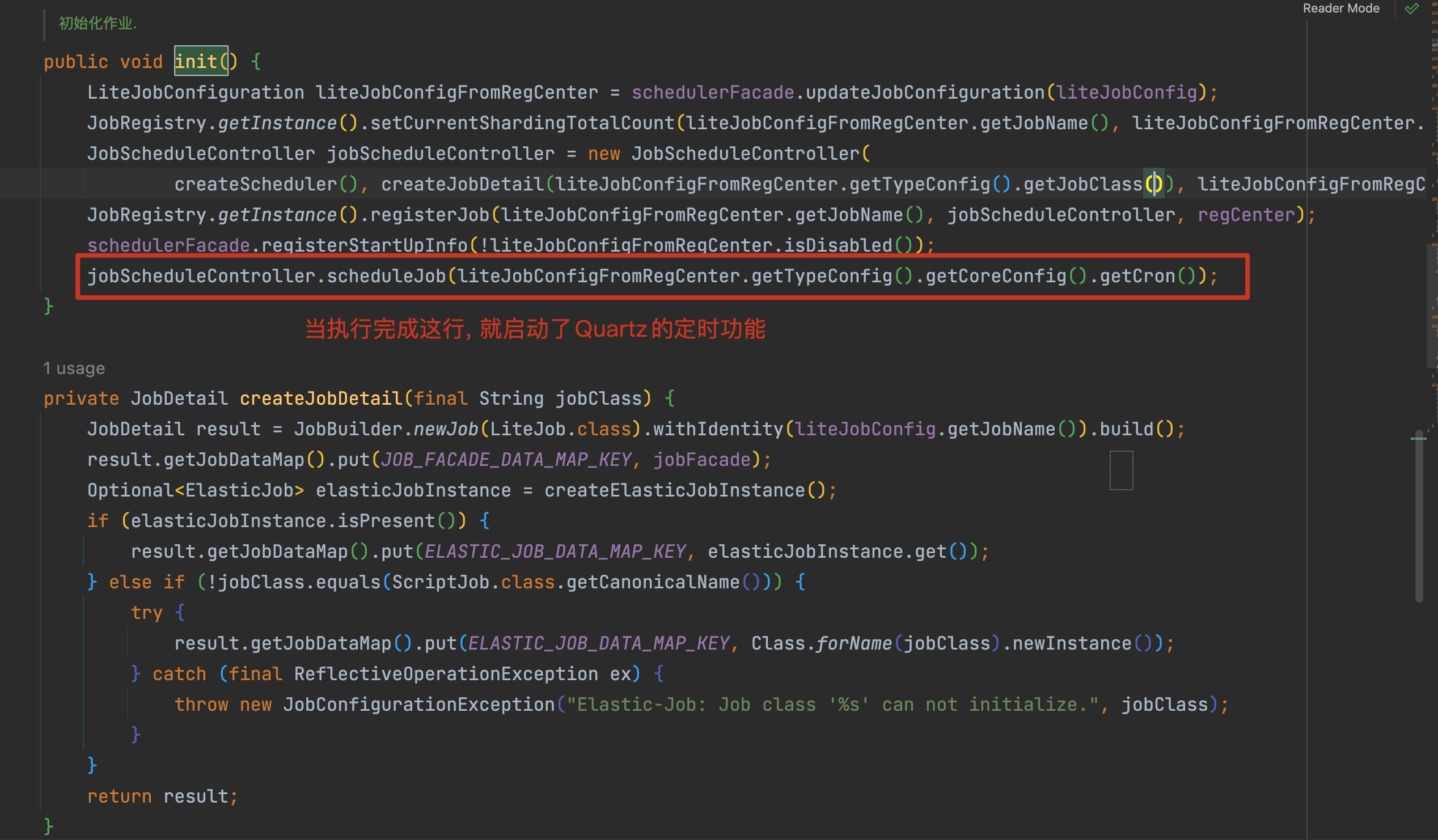
init方法中启动定时器,可以看到内部核心还是由quartz来实现的和小编在上一篇写的quartz很类似
public void scheduleJob(final String cron) {
try {
if (!scheduler.checkExists(jobDetail.getKey())) {
scheduler.scheduleJob(jobDetail, createTrigger(cron));
}
scheduler.start();
} catch (final SchedulerException ex) {
throw new JobSystemException(ex);
}
}
1
2
3
4
5
6
7
8
9
10
2
3
4
5
6
7
8
9
10
然后根据任务类型生成指定类型的执行器,并执行
@NoArgsConstructor(access = AccessLevel.PRIVATE)
public final class JobExecutorFactory {
/**
* 获取作业执行器.
*
* @param elasticJob 分布式弹性作业
* @param jobFacade 作业内部服务门面服务
* @return 作业执行器
*/
@SuppressWarnings("unchecked")
public static AbstractElasticJobExecutor getJobExecutor(final ElasticJob elasticJob, final JobFacade jobFacade) {
if (null == elasticJob) {
return new ScriptJobExecutor(jobFacade);
}
if (elasticJob instanceof SimpleJob) {
return new SimpleJobExecutor((SimpleJob) elasticJob, jobFacade);
}
if (elasticJob instanceof DataflowJob) {
return new DataflowJobExecutor((DataflowJob) elasticJob, jobFacade);
}
throw new JobConfigurationException("Cannot support job type '%s'", elasticJob.getClass().getCanonicalName());
}
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
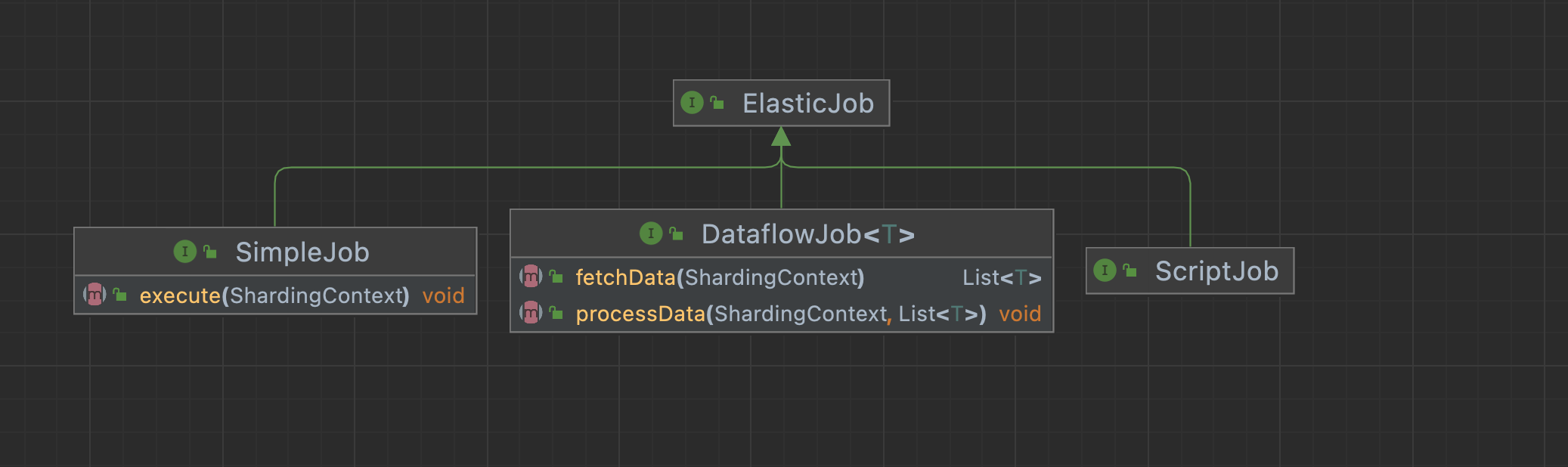
任务类型对应的执行器是下面这些
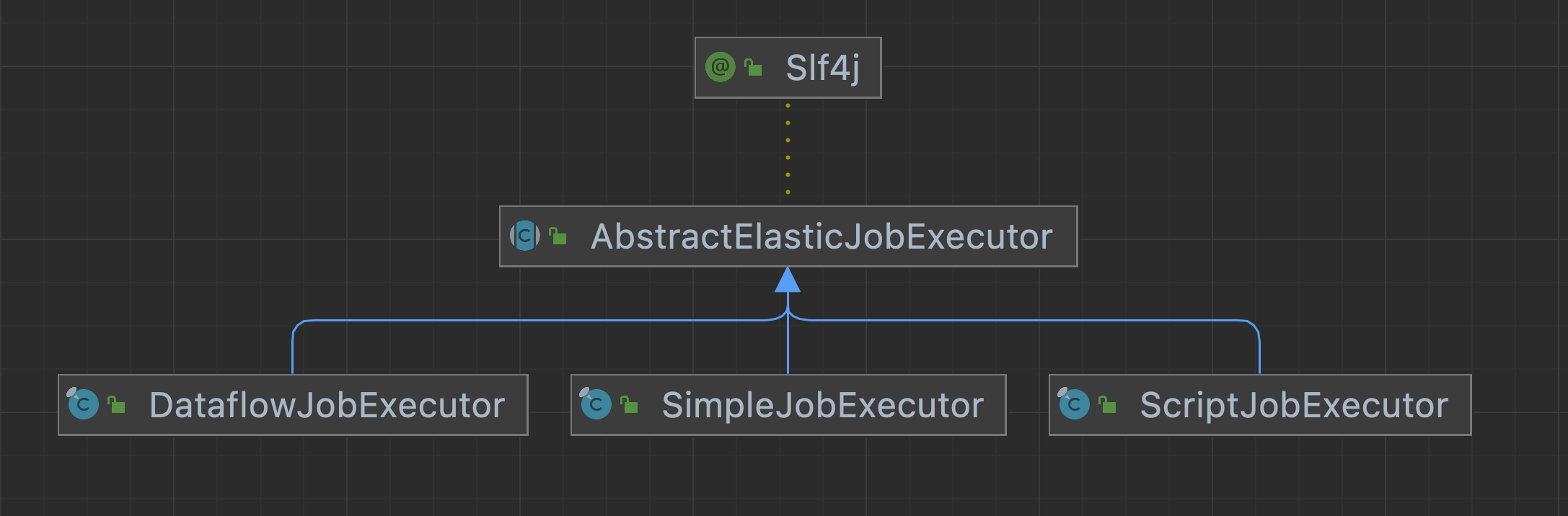
从中我们分析最常见的任务类型SimpleJobExecutor,这里面我们主要看ShardingContext分片上下文是怎么生成的,很明显是有抽象类AbstractElasticJobExecutor来生成的。分片策略一定也是在这个里面执行的,最终生成ShardingContext类的,而这个类就是Elastic-Job给每台服务器上的任务分配的上下文,这里面就包括了分配标识

# 分片策略如何使用
给分布式环境下的每个任务实例, 一个特定的分片标记。然后每个任务实例中根据分片标记去获取数据。以此来避免任务重复执行。那么究竟是如何避免呢? 其实还是开发者自己来避免的, job只保证同一个分片只会分到一个实例上,不会分配到两个实例上。
public class InvokerTimer implements SimpleJob{
@Autowired
private Core core;
public void execute(ShardingContext shardingContext){
// 获取分片信息
int item = shardingContext.getShardingItem();
// 根据分片信息,获取这台实例上应该处理的数据
List<String> orgIds = core.queryOrgIdsByScheduleZone(item);
...
}
}
1
2
3
4
5
6
7
8
9
10
11
12
13
2
3
4
5
6
7
8
9
10
11
12
13
# Elastic-Job的三种分片策略
什么是分片策略呢? 什么情况下有分片策略呢? 其实这就是Elastic Job 作为分布式任务的亮点。就是通过分片的策略,来给每台实例指定数据,防止多台实例重复处理数据。 ElasticJob 是通过Zookeeper来进行交互和分配任务,这里说分配任务有点夸大了他的能力,他其实只是给你个分片,然后开发者根据分片去自己到数据库或者是其他数据源中拿到,改分片对应的 任务来执行。而我们所谓说的分片就是ShardingContext对象。就是说ElasticJob把你生成了ShardingContext。ElasticJob提供了3中策略。
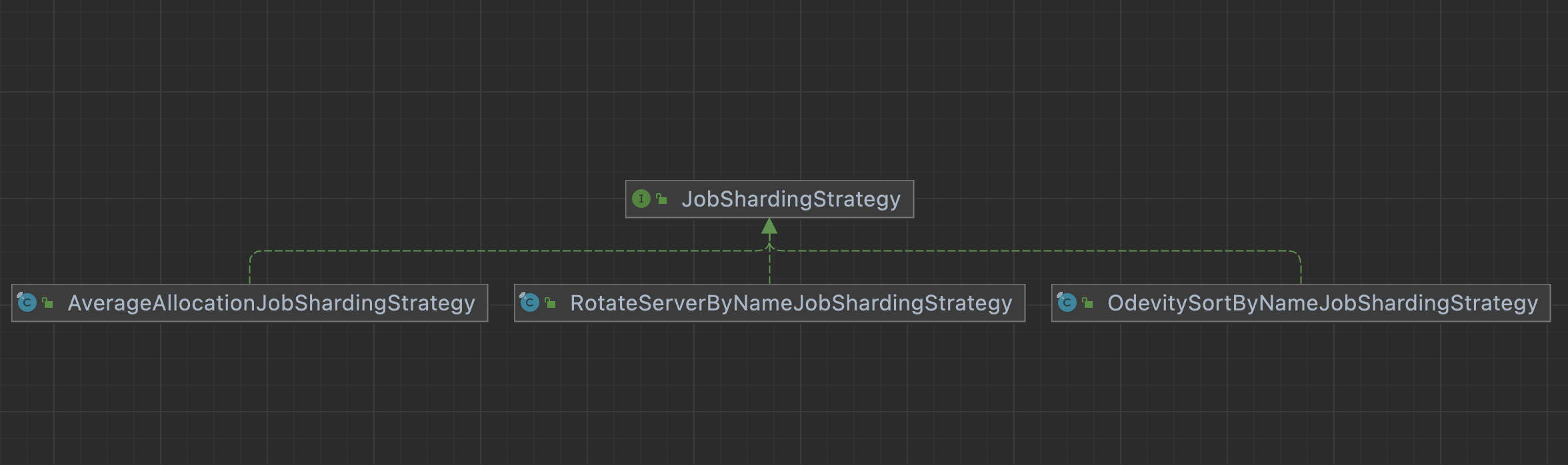
# 平均分片
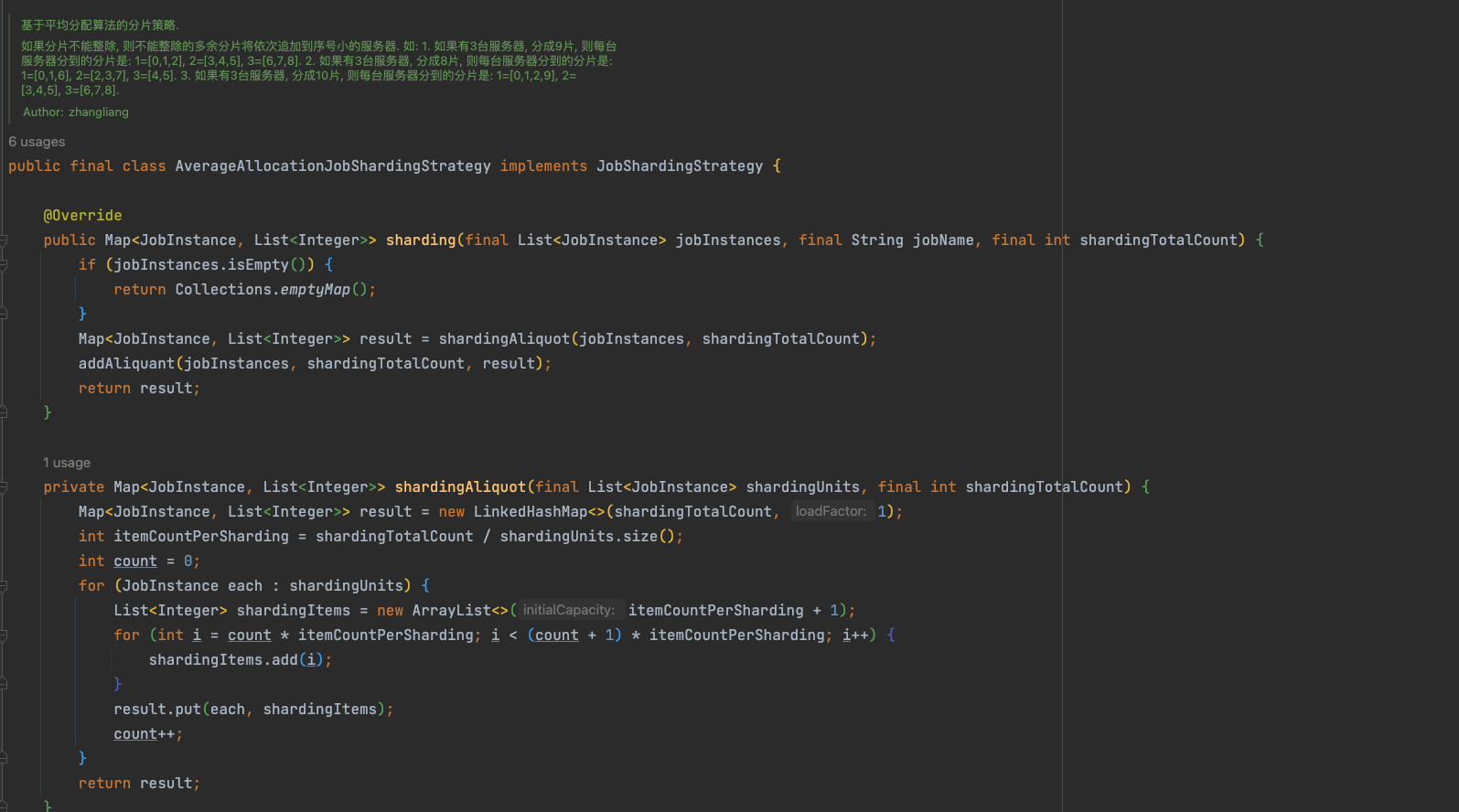
AverageAllocationJobShardingStrategy 平均分片
如果分片不能整除, 则不能整除的多余分片将依次追加到序号小的服务器.
如:
如果有3台服务器, 分成9片, 则每台服务器分到的分片是: 1=[0,1,2], 2=[3,4,5], 3=[6,7,8]. 如果有3台服务器, 分成8片, 则每台服务器分到的分片是: 1=[0,1,6], 2=[2,3,7], 3=[4,5]. 如果有3台服务器, 分成10片, 则每台服务器分到的分片是: 1=[0,1,2,9], 2=[3,4,5], 3=[6,7,8].
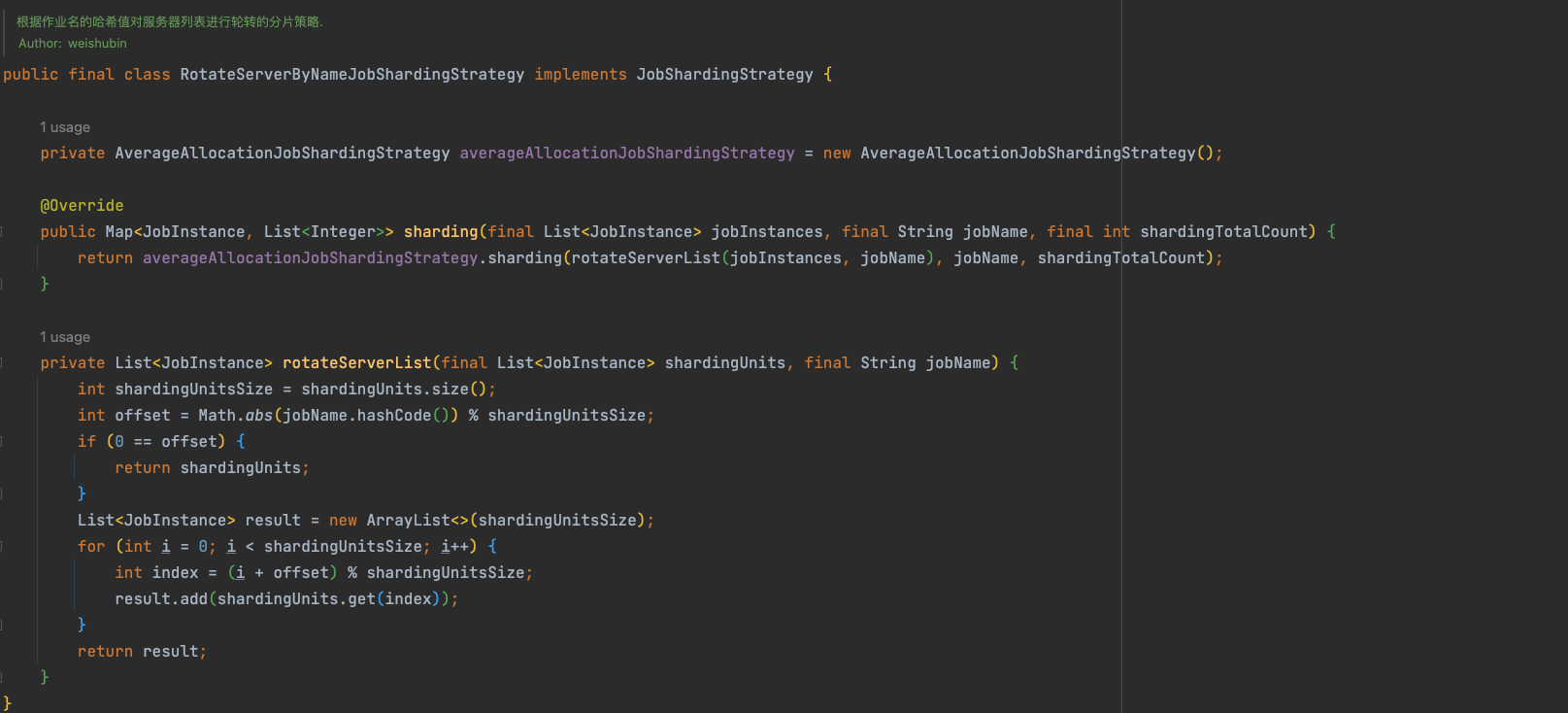
# hash 分片
根据作业名的哈希值奇偶数决定IP升降序算法的分片策略.
- 作业名的哈希值为奇数则IP升序.
- 作业名的哈希值为偶数则IP降序. 用于不同的作业平均分配负载至不同的服务器.
如:
- 如果有3台服务器, 分成2片, 作业名称的哈希值为奇数, 则每台服务器分到的分片是: 1=[0], 2=[1], 3=[].
- 如果有3台服务器, 分成2片, 作业名称的哈希值为偶数, 则每台服务器分到的分片是: 3=[0], 2=[1], 1=[].

# 轮训分片
# 分片策略总结
通过对上面的分片策略来看啊,这所谓的三种分片策略其实都是利用AverageAllocationJobShardingStrategy 平均分片,非常巧妙也非常敷衍😂。
巧妙是说充分利用了平均分片的策略,只不过将serverList排序就实现了另一种分片策略,敷衍是说没有多大作用。其实完全可以实现通过机器性能的监控同步到ZK,然后在根据机器性能来平均分片的,这样小编感觉更加合理写。不过因为Elastic Job提供了指定策略的接口,所以具体怎么分的能力,就交给使用者自己去实现吧。
对于根据作业名轮询策略和IP降级策略,小编无话可说,不知道到底好用不好用,以及有啥实际用处。不过小编在工作中一直用平均策略。说到这里我们顺便分析下如何自定义分片策略。
# 如何自定义分片策略
我们先看源码是从哪里弄到分片策略信息的
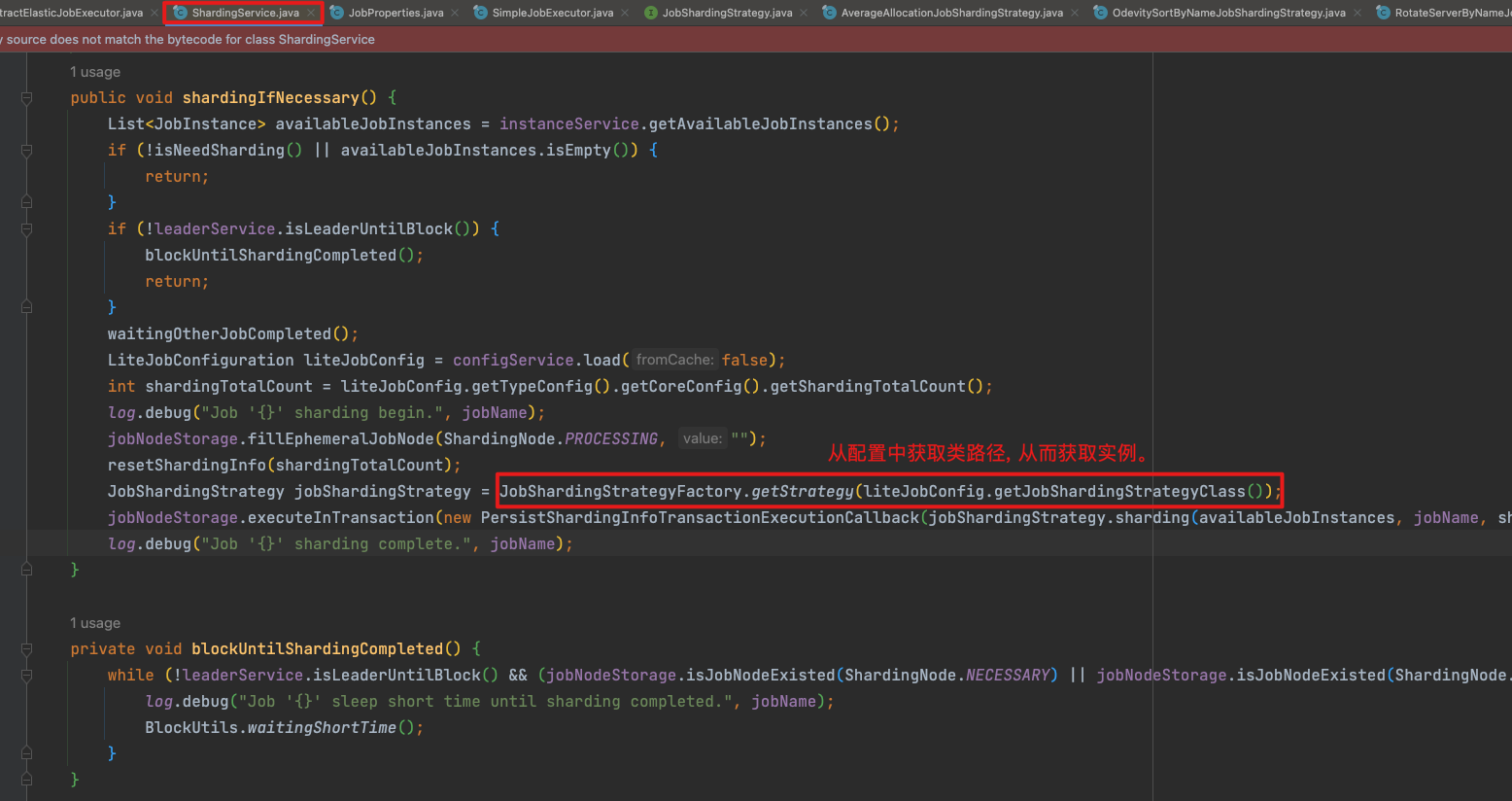 从配置中读取分片策略class属性值
从配置中读取分片策略class属性值

自定义分片策略class 如果没有指定默认平均分,在JobShardingStrategyFactory中指定默认
public final class JobShardingStrategyFactory {
/**
* 获取作业分片策略实例.
*
* @param jobShardingStrategyClassName 作业分片策略类名
* @return 作业分片策略实例
*/
public static JobShardingStrategy getStrategy(final String jobShardingStrategyClassName) {
if (Strings.isNullOrEmpty(jobShardingStrategyClassName)) {
return new AverageAllocationJobShardingStrategy();
}
try {
Class<?> jobShardingStrategyClass = Class.forName(jobShardingStrategyClassName);
if (!JobShardingStrategy.class.isAssignableFrom(jobShardingStrategyClass)) {
throw new JobConfigurationException("Class '%s' is not job strategy class", jobShardingStrategyClassName);
}
return (JobShardingStrategy) jobShardingStrategyClass.newInstance();
} catch (final ClassNotFoundException | InstantiationException | IllegalAccessException ex) {
throw new JobConfigurationException("Sharding strategy class '%s' config error, message details are '%s'", jobShardingStrategyClassName, ex.getMessage());
}
}
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
