
面试再也不怕被HashMap欺负了
西魏陶渊明 ... 2022-1-4 大约 4 分钟

作者: 西魏陶渊明 博客: https://blog.springlearn.cn/ (opens new window)
西魏陶渊明
莫笑少年江湖梦,谁不少年梦江湖
HashMap是我们在日常开发中经常使用的一个结合类型,同时也是面试时候最好提问的集合类型,在这里进行整理 一起学习,进步。
# 一、数据结构
先说两种数据结构, 不用怕, 如果要对付面试只要了解就行了。不用手写实现, 同时也因为已经有人帮我写好,所以开发中我们只要用就行。
# 1. 二叉树
本来是一个相对平衡的二叉树(当前数据 > 根节点 ? 从右边插入 : 从左边插入)。
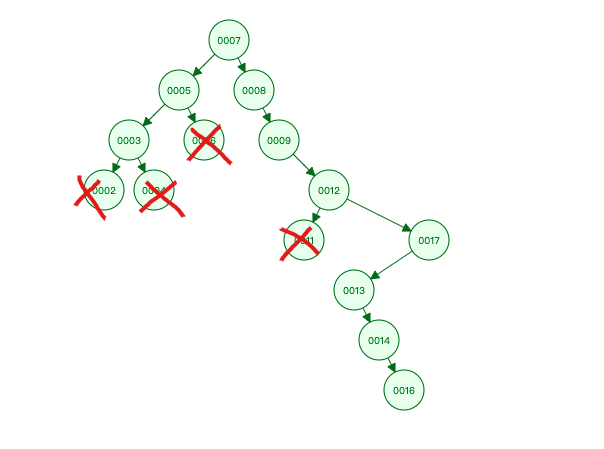 但是由于在使用的过程中的删除,慢慢的变成了一个瘸腿。此时树的高度越高,数据越多,导致查询叶子
的耗时越长。
但是由于在使用的过程中的删除,慢慢的变成了一个瘸腿。此时树的高度越高,数据越多,导致查询叶子
的耗时越长。

于是乎人们在这个数据结构的基础上,研究出新的结构,就是下面的红黑树。
# 2. 红黑树
依次插入7 5 3 2 4 6 8 9 12 11 17 13 14 16
很明显我们可以看出红黑树比二叉树相对比较平衡。
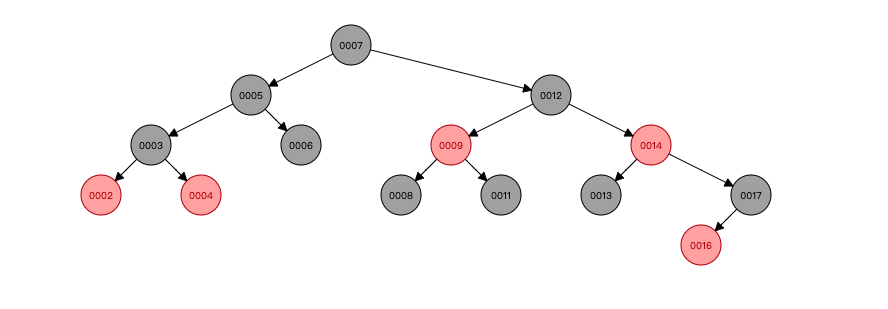
在对比一下二叉树

好了关于数据结构的知识就说这么多,可以通过图就能知道这两种数据结构情况了。因为数据结构不是我们本篇研究的点。 所以就提这么多。
# 二、源码分析
HashMap 实现了 Map 接口,JDK1.7由 数组 + 链表实现, 1.8后由 数组 + 链表 + 红黑树实现

# 1. put的源码分析
HashMap中声明的常量信息,注意看。下面源码中会提到。
| 变量 | 含义 |
|---|---|
| DEFAULT_INITIAL_CAPACITY | 默认的初始容量 |
| MAXIMUM_CAPACITY | 最大的容量2^30 |
| DEFAULT_LOAD_FACTOR | 容器个数 size > 负载因子 * 数组长度 就需要进行扩容 |
| TREEIFY_THRESHOLD | 如果数组中某一个链表 >= 8 需要转化为红黑树 |
| UNTREEIFY_THRESHOLD | 如果数组中某一个链表转化为红黑树后的节点 < 6 的时候 继续转为 链表 |
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
//判断是否是树
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
//继续用链表
else {
// 循环链表
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
// 新建节点存储
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
//大于树的阀值,就转换为树结构
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
从上面源码中我们可以看到在put时候会判断是链表结构还是红黑树。如果是树就用树put
((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);。
如果是链表就循环列表插入数据,如果发现列表长度大于树的阀值就讲链表转换为树
# 2. put流程赘述
- 判断 table 是否为 null。为 null 则新建一个 table 数组
- 调用 hash 获取 该 key 的 hash 值
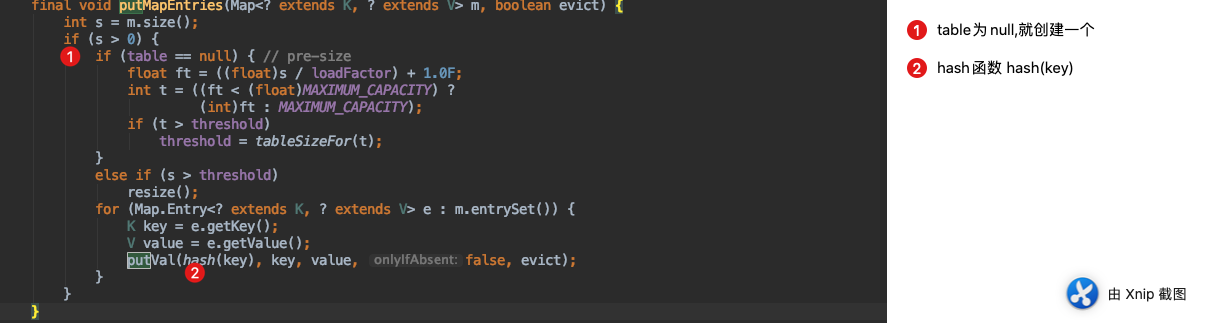
- 将hash & n-1的值当做下标去找数据
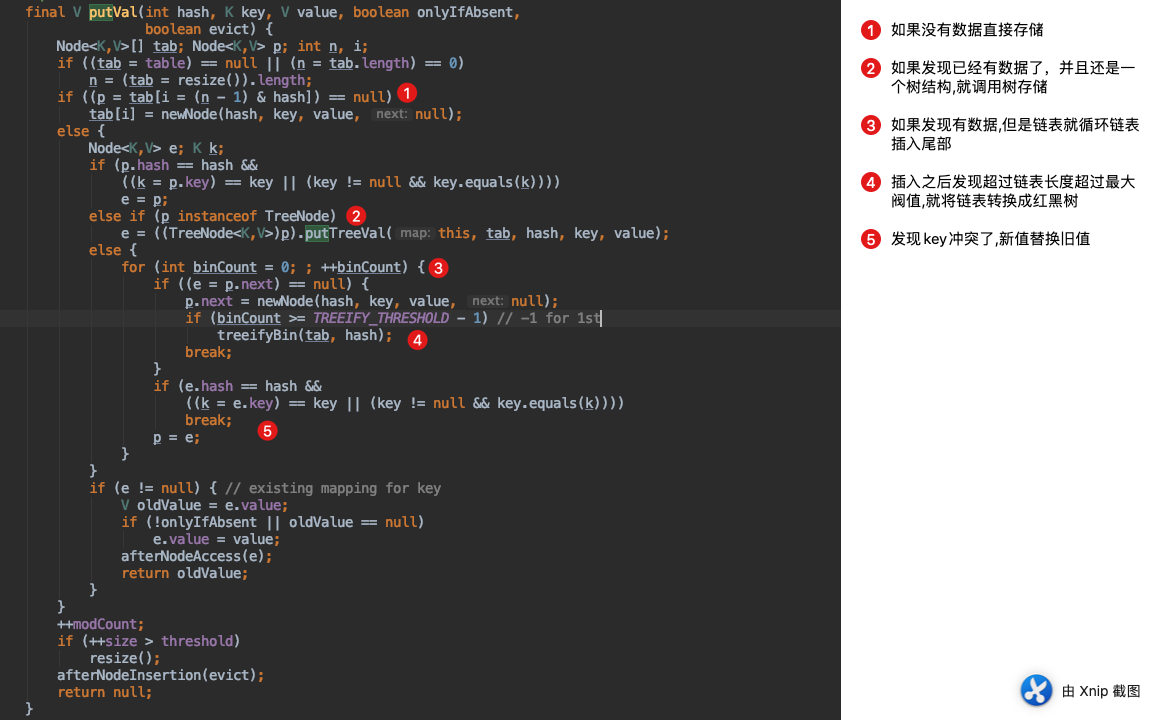
- 如果发现有数据
- 但是数据的hash和key都和当前要插入的一致就替换。(此时还是一个Node节点)
- 但是数据的hash一致,但是key不一致,说明是hash冲突了。就转换成一个Node链表,数据放到链表尾部
- 如果发现链表长度大于等于8,就转换成红黑树
# 三、面试知识扩展
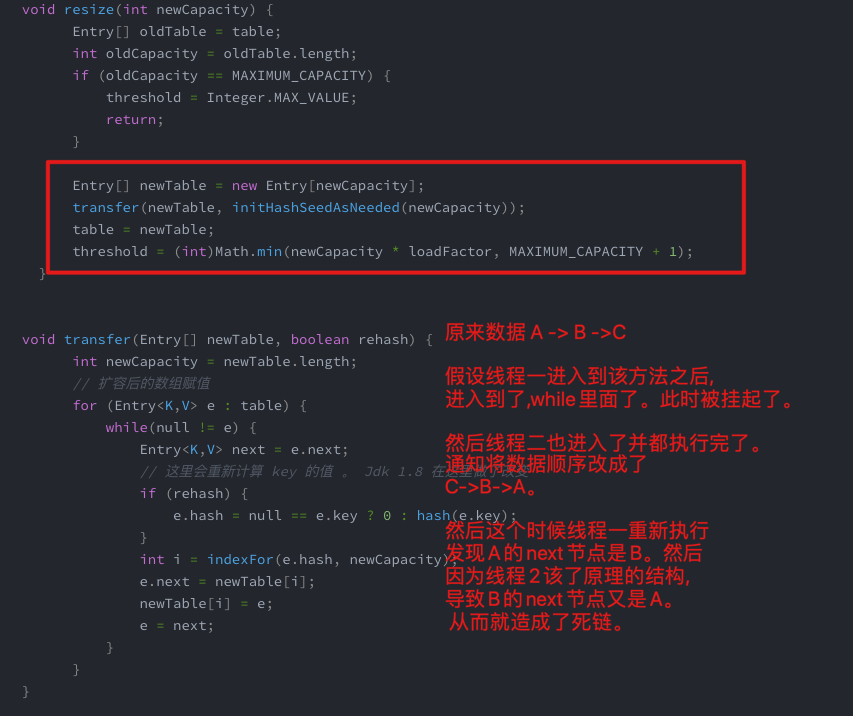
前面我们知道了HashMap在1.8之后的优化。这里我们最后再说一个面试题。 问: 1.7时候hashmap在扩容时候回出现死链的问题。问题原因是什么? 已经出现的场景是什么?
首先看下扩容方法 resize 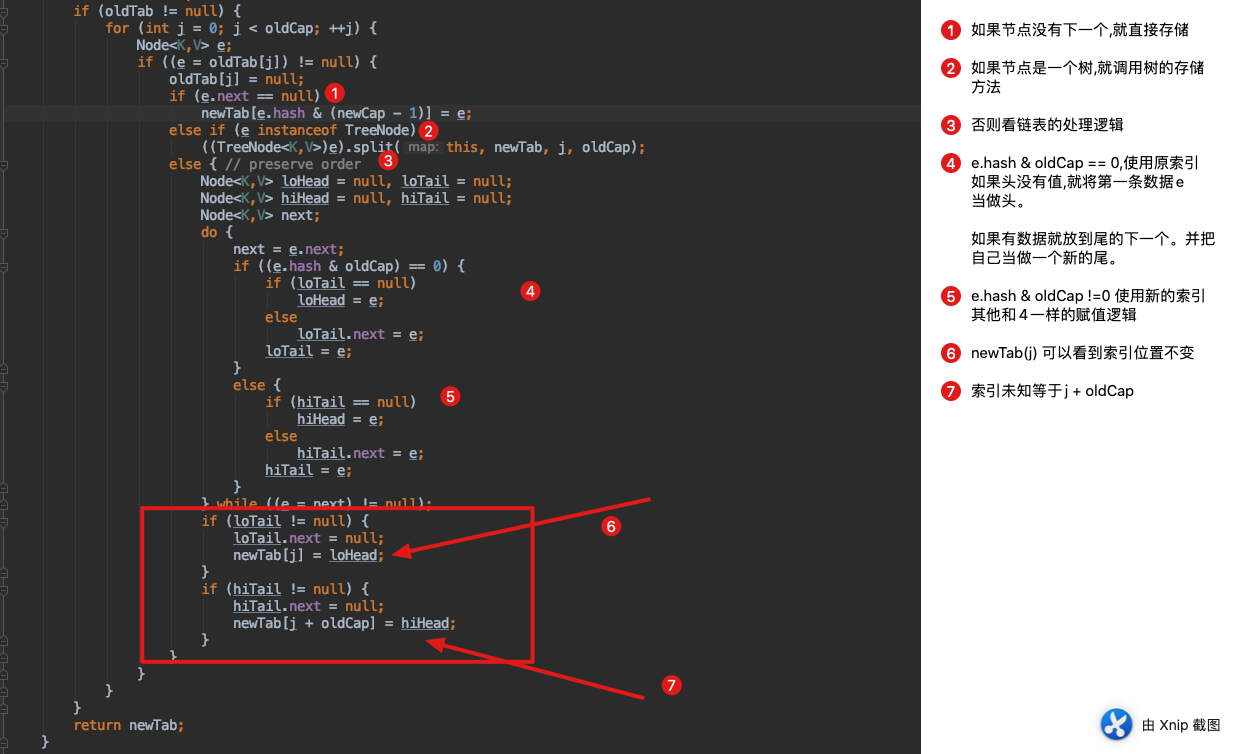
# 1. 优化1
jdk1.8在对链表进行扩容时候时候不是直接都去hash了。而是
(e.hash & oldCap) == 0 下标不变
(e.hash & oldCap) != 0 下标 = 原下标 + oldCap
# 2. 出现的场景
多线程操作扩容
最后求关注,求订阅,谢谢你的阅读!
